参考http://blog.csdn.net/weixinhum/article/details/77046873
最近项目需要用到人脸训练和检测的东西,选用了OpenFace进行,因而有此文。
本人主要参考了下面的这两篇博客:
如有雷同,绝非偶然。
1.python
Ubuntu 16.04桌面版自带python
2.git
$ sudo apt-get install git
- 1
3.编译工具CMake
$ sudo apt-get install cmake
- 1
4.C++标准库安装
$ sudo apt-get install libboost-dev$ sudo apt-get install libboost-python-dev
- 1
- 2
5.下载OpenFace代码
$ git clone https://github.com/cmusatyalab/openface.git
- 1
6.OpenCV安装
$ sudo apt-get install libopencv-dev$ sudo apt-get install python-opencv
- 1
- 2
7.安装包管理工具pip
$ sudo apt install python-pip
- 1
更新pip,按上面安装不知道为什么是旧的版本,可能影响下面的操作
$ pip install --upgrade pip
- 1
8.安装依赖的 PYTHON库
$ cd openface$ sudo pip install -r requirements.txt$ sudo pip install dlib$ sudo pip install matplotlib
- 1
- 2
- 3
- 4
- 5
9.安装 luarocks—Lua 包管理器,提供一个命令行的方式来管理 Lua 包依赖、安装第三方 Lua 包等功能
$ sudo apt-get install luarocks
- 1
10.安装 TORCH—科学计算框架,支持机器学习算法
$ git clone https://github.com/torch/distro.git ~/torch --recursive$ cd torch $ bash install-deps $ ./install.sh
- 1
- 2
- 3
- 4
使 torch7 设置的刚刚的环境变量生效
$ source ~/.bashrc
- 1
这里只安装了CPU版本,后面如果需要再更新CUDA的使用方法
11.安装依赖的 LUA库
$ luarocks install dpnn
- 1
下面的为选装,有些函数或方法可能会用到
$ luarocks install image$ luarocks install nn$ luarocks install graphicsmagick$ luarocks install torchx$ luarocks install csvigo
- 1
- 2
- 3
- 4
- 5
12.编译OpenFace代码
$ python setup.py build$ sudo python setup.py install
- 1
- 2
13.下载预训练后的数据
$ sh models/get-models.sh$ wget https://storage.cmusatyalab.org/openface-models/nn4.v1.t7 -O models/openface/nn4.v1.t7
- 1
- 2
————————-到此配置完成,下面是简单的例子————————-
可以用compare.py(demo文件夹中)给出的示例检测两张脸的相近程度。
$ python demos/compare.py { 3.jpg*,4.jpg*} - 1
1.jpg

2.jpg

3.jpg

4.jpg

结果如下
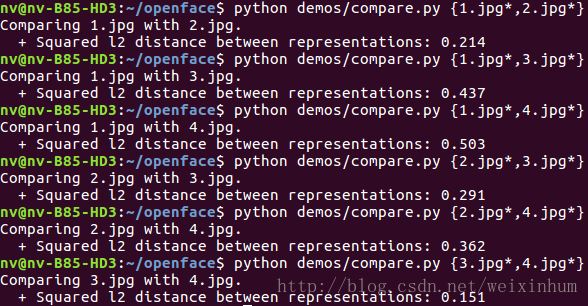
可以看到,相同人物之间的距离明显比不同人物要小。
注:在运行时,最好加上图片路径(将需要测试的图片上传到images文件夹)
python demos/compare.py ./images/{1.jpeg*,2.jpeg*} 上传命令:
scp 1.jpeg yanjieliu@192.168.1.139:/home/yanjieliu/opt/openface/images/
另外也可以像开始提到的参考文章中一样,写一个检测人脸的程序进行检测,名称为face_detect.py,代码如下:


import argparseimport cv2import osimport dlibimport numpy as npnp.set_printoptions(precision=2)import openfacefrom matplotlib import cmfileDir = os.path.dirname(os.path.realpath(__file__))modelDir = os.path.join(fileDir, '..', 'models')dlibModelDir = os.path.join(modelDir, 'dlib')if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument( '--dlibFacePredictor', type=str, help="Path to dlib's face predictor.", default=os.path.join( dlibModelDir, "shape_predictor_68_face_landmarks.dat")) parser.add_argument( '--networkModel', type=str, help="Path to Torch network model.", default='models/openface/nn4.v1.t7') # Download model from: # https://storage.cmusatyalab.org/openface-models/nn4.v1.t7 parser.add_argument('--imgDim', type=int, help="Default image dimension.", default=96) # parser.add_argument('--width', type=int, default=640) # parser.add_argument('--height', type=int, default=480) parser.add_argument('--width', type=int, default=1280) parser.add_argument('--height', type=int, default=800) parser.add_argument('--scale', type=int, default=1.0) parser.add_argument('--cuda', action='store_true') parser.add_argument('--image', type=str,help='Path of image to recognition') args = parser.parse_args() if (None == args.image) or (not os.path.exists(args.image)): print '--image not set or image file not exists' exit() align = openface.AlignDlib(args.dlibFacePredictor) net = openface.TorchNeuralNet( args.networkModel, imgDim=args.imgDim, cuda=args.cuda) cv2.namedWindow('video', cv2.WINDOW_NORMAL) frame = cv2.imread(args.image) bbs = align.getAllFaceBoundingBoxes(frame) for i, bb in enumerate(bbs): # landmarkIndices set "https://cmusatyalab.github.io/openface/models-and-accuracies/" alignedFace = align.align(96, frame, bb, landmarkIndices=openface.AlignDlib.OUTER_EYES_AND_NOSE) rep = net.forward(alignedFace) center = bb.center() centerI = 0.7 * center.x * center.y / \ (args.scale * args.scale * args.width * args.height) color_np = cm.Set1(centerI) color_cv = list(np.multiply(color_np[:3], 255)) bl = (int(bb.left() / args.scale), int(bb.bottom() / args.scale)) tr = (int(bb.right() / args.scale), int(bb.top() / args.scale)) cv2.rectangle(frame, bl, tr, color=color_cv, thickness=3) cv2.imshow('video', frame) cv2.waitKey (0) cv2.destroyAllWindows() 